The perfect PaaS: Does it exist? Or impossible to build?
Warning: This article is a combination of deep multi-month research, hands-on experience over almost a decade, and ideas, all combined into a nice elaborated ranting. Proceed at your own peril!
Table of contents
- Intro
- This question haunts me
- What do I want from a platform?
- Pricing
- Compute
- Continuous Integration & Continuous Deployment (CICD)
- Flexibility and extensibility
- Good citizen
- Developer experience (DX or DevX)
- My complaint to AWS
- Conclusion
- The question remains
Intro
Over the past 5 months, I have spent my entire free time outside working hours, researching, trying, and reading documentation about every cloud platform product I could get my hands on. From Platform-as-a-Service (PaaS), to self-hosted PaaS, to Backend-as-a-Service (BaaS), to traditional server management tools, to Infrastructure as Code (IaC) tools, to the newer and trendier Infrastructure from Code (IfC) tools, and everything in between.
I was still left disappointed with the existing offerings.
At some point, I even started being serious about building the platform I want myself. And then, once my own needs are satisfied, making it a product for others to use as well. Because, what’s a better business than one that solves your own problem, right? 😁
In a nutshell, I was (and still am) looking for a platform to use in order to deploy my stupid no-revenue nobody-uses toy projects, but also my more serious need-it-to-always-run might-bring-me-money projects.
I am a software engineer by trade, and over the years I have used a variety of platforms. During my time at Amazon, I started with our pre-AWS internal system (Apollo), but then (thank God) we migrated on AWS where I used and built several abstractions with raw AWS Cloudformation (and sprinkles of Jinja), then AWS SAM, and then AWS CDK. Similarly, at Meta we had our own internal deployment platform(s), and now at Datadog, we have yet another internal platform built on-top of Kubernetes (K8s).
Even within Amazon, every single team was building directly on-top of AWS, so you can imagine every team building their own mini platform and abstractions. Some were doing it really well, and some were doing it horribly bad… The funny part was that the final result of each team’s infrastructure and their CICD pipelines looked similar (at least the good ones). It was then, during my time working with AWS, that I started imagining what the ideal platform would look like, having seen the things that worked well, and the mistakes that nobody should ever repeat.
After all this time, I still haven’t found the platform that gives me everything I want. There are a few that come really close, but then fail me in some way.
This question haunts me
Does the perfect PaaS exist, or is it impossible to build?
There are tens of startups launched in this domain every year (joke tweet 1, joke tweet 2), but they either shut down after a few months, or they pivot into something entirely different, or they are just not good enough.
Is the perfect platform just a mirage? Why doesn’t it exist? Or does it, and I just haven’t found it yet?
Almost everyone I know (including myself) uses a combination of at least 2-3 platforms, integrating them with Infrastructure-as-Code templates, and then managing and running those templates in yet another Continuous Integration (CI) platform.
This is OK if you work on one project, but I don’t want to do it for every single project I work on.
Am I wasting my time on something that cannot be built? Is every person, and every team, really all that different to justify each building their own platform?
The front-end folks managed to converge in beautiful platforms, with Cloudflare Pages, Vercel, and Netlify, providing a very compelling package. I like them, and I use them. But sometimes they are too restricted and get super pricy when you want to lift those restrictions (read my serverless platforms overview back in 2022), which is when I fallback to a full-stack platform again.
I still believe that the platform I imagine can satisfy the needs of many people, and many teams.
What do I want from a platform?
I want the Heroku developer experience (DX) on-top of AWS. That’s it, that’s the buy pitch.
AWS is super powerful, reliable, with pay-as-you-go pricing. I love it. However, the developer experience using AWS directly is abysmal. I experienced AWS from the inside, and I know they won’t fix this. At least not any time soon.
Some folks joke that Heroku is the Heroku experience on-top of AWS. But I disagree. Heroku being built on-top of AWS is an implementation detail I don’t care about. I want the products AWS offers (or similar), the EC2s, the ECSs, the Lambdas, the DynamoDBs, and the S3s. But, I want them packaged in a Heroku experience.
Pricing
Pricing is a huge thing for any company. Pricing defines, and filters, the customers a company will attract. Do you want the Enterprises, charge thousands. Do you want the indie developers, give stuff for free. The pricing model is what will make a company profitable, or kill it.
Having said that, for me, as a customer, I like it more when pricing starts from zero ($0) when I don’t consume any resources, and increases as I use the platform more.
This pricing model has many names and variations: pay as you go, metered, usage-based, and nowadays a core component of any serverless product.
If you don’t use something you don’t pay, and the more you use something the more you pay.
I want to be able to host my toy projects that have literally 0 requests-per-second for cents, but I am happy to pay more for the projects I care about being available.
While looking through products, I tend to compare their compute pricing with AWS EC2, and anything that is within 2x of EC2 costs feels OK to me.
For comparison, Heroku costs 5-10x (or higher) more than AWS once we go past the entry-level dynos (what they call their instances): Performance M for $250/dyno/month vs EC2 m6g.medium for $33.58/instance/month.
Most new platforms also fail in the pricing dimension, and are way more expensive than what I would pay for my workload.
Some platforms take a cut of the AWS bill for the resources they manage, which to me is nuts. The value I get from their platform doesn’t depend on the instance types I use (ten instances of t4g.nano vs c6g.2xlarge) so why should my bill. Others charge per seat ($99/seat is getting quite popular) in addition to actual compute charges, which again seems off for me.
Pricing is tricky, and I totally understand that for a company that pays $50K+ a year for an engineer, it doesn’t matter if the pay $1000 more for the tools they use. They need to make a profit at the end of the day. Personally, I prefer usage-based pricing models, even if the unit-price is a bit higher in low volumes.
I thought about pricing a lot. The model I would choose if I ever built it would be two-fold:
- Provide usage-based pricing that starts from
$0, but with a higher price-per-unit. - Provide per-seat or volume-discounted pricing for bigger companies.
With the above two-fold model, anyone can start using the platform to make sure it works for them, pay for their usage along the way, and once they settle to use it they could switch to the second pricing plan. Some prefer predictability, some prefer usage-based, so why not both.
Basecamp actually just updated their pricing to a two-fold model, just this month. As of this writing, they offer a per-user $15/month plan, but also a flat $299/month plan for unlimited use.
That’s what ideal pricing looks to me! In this case it’s not stricly usage-based, but their low per-seat price is pretty close to the above model.
I love how easy it is to start using and ramping up with managed pay-as-you-go products like AWS DynamoDB, S3, and even non-AWS products like the new Momento Serverless Cache that charges $0.15/GB and that’s it. One price to think; it can’t get simpler than that.
Compute
This is the dimension where most of the platforms have the most restrictions, or limitations.
I am not going to focus on serverless functions in this article (although similar things apply), since a few things are more different when you go with a full-on serverless architecture (cold-starts, event-driven services, queues, frameworks, etc).
Coincidentally, exactly one year ago I wrote a deep dive article for AWS Elastic Beanstalk, explaining why I liked it, and elaborated on its feature set along with some of its nuances. That article was actually triggerred by this tweet I made voicing once again my frustration in finding my ideal platform (@LambrosPetrou/status/1487493396566528007).
There are three types of services that I want to run:
- The toy project that is fine to have a bit of cold-start, and doesn’t receive much traffic.
- An application that needs to be available, to have low latency (<100ms), and potentially auto-scale (1-5 nodes).
- An application (e.g. Gitea) that needs persistent disk access, hence a single-instance server, and which ideally shouldn’t have (long) downtime during deployments.
For the first type, I always use serverless functions with AWS Lambda, or Cloudflare Workers.
The second and third types is where restrictions come in play.
Compute / Requirements
- Managed platform: OS updates, host patching, and optionally language runtime updates
- Single server instance should be possible (because not everything is web-scale)
- Persistent disk volumes (i.e. Amazon EBS)
- Deployments in-place on same instance with only 1-2s of downtime (maximum)
- Restriction due to the disk volume only being accessible from one host at a time
- Variety of instance types, from the low-cost T3 to the powerful ARM-based Graviton2 C6g
- Autoscaled cluster possible when needing more than one instance
Compute / What is missing?
My evaluation of a platform most often looks like this:
- I need persisted disk volumes (e.g. for SQLite), and many platforms automatically fail (e.g. Google Cloud Run).
- I prefer a managed platform taking care of OS updates, patches, etc. In most cases, this automatically means using containers. I couldn’t find any platform outside AWS Elastic Beanstalk that does this without containers. I could also consider the various server management platforms (e.g. Linode) but even if they offer patches and updates, it’s not as convenient as a truly managed runtime, and they lack everything else too.
- Most platforms that survive up to this step will fail the in-place deployments requirement. In-place deployments are a must when you have a persistent disk volume attached, otherwise you end up with long downtimes (stop using instance, detach volume, attach volume to new instance, start using new instance). AWS Elastic Beanstalk does this with only 1-2s downtime. Alternatively, I could use my own custom setup with AWS CodeDeploy & EC2.
- We only reach this step when considering the autoscaled cluster application, and probably we are using containers since not many platforms support executables natively. This is OK.
Summarising, when I have a Go application executable to deploy, my choices are:
- Single-instance: Use AWS Elastic Beanstalk, or do my own thing with AWS CodeDeploy & EC2
- Autoscaled cluster: Use AWS Elastic Beanstalk, AWS ECS, Fly.io, or other container platform.
Continuous Integration & Continuous Deployment
This is a huge topic (I am building a course about it), and products vary from a very basic Continuous Integration (CI) feature, to complex Continuous Deployment (CD) pipelines.
CICD / Requirements
- Support for multiple AWS accounts (if the platform deploys in my own accounts)
- Support for multiple regions, and multiple stages (staging, production, waves)
- Support for custom build steps, and potentially per region when necessary
- Support for different deployment targets (see the #Compute section above)
- Support for automatic approval workflows (e.g. acceptance tests)
- Support for manual approval between stages (because not everything can be automated)
- Support for automatic rollback using some monitor/alert/metric/workflow
- Track commits progressing across the pipeline
- Logs and metrics per build/deployment/job
CICD / What is missing?
Everything? 😅 Jokes aside, I believe that working with the internal Amazon Pipelines tool for almost 5 years spoiled me.
There is not much public information on the tool, and no, AWS CodePipeline is not similar, it doesn’t even come close. However, the following two articles (personal favourites) from the Amazon Builders’ Library give a very detailed explanation for the core aspects of how deployments happen inside Amazon/AWS.
At a first glance, the list of requirements above might seem a lot. I would argue that all the above should be part of every CICD pipeline, and in my experience, all the teams end up implementing something close to that on their own after a few months of working on a project. So, why not have it built-in to the platform. Almost all good pipelines at Amazon “looked the same”, albeit with their own steps, approval workflows, and monitors to track when to roll back.
Most cloud platforms do not support such complex pipelines at all. Usually, they only provide single stage build/deploy workflows off a branch, and they offload the CICD needs to external dedicated products.
The majority of projects I see default in using Github Actions. It’s indeed a really nice product, but it has many limitations, and requires you to buy into the more expensive plans to enable some core features. I believe that a major part of its success is mostly due to the network effects of being free and readily available for anyone on Github.
Gitlab CI and Buildkite are among the best products I found, and I explored more than 20 of them. They are also the only ones supporting dynamically generated pipelines (in Gitlab, in Buildkite). This is very useful when you have a fixed initial pipeline, but then some configuration in your code, or the output of a step, determines the next steps in the pipeline. This is not a common feature, but it’s really useful for a project I am working on that automatically generates the infrastructure and deployment stages based on some configuration during the workflow runtime.
However, both have their own issues, high pricing for Gitlab, and managing the server-fleet for Buildkite. The pricing for CICD products also varies a lot, from per seat pricing, to usage-based pricing, from affordable, to crazy expensive.
Flexibility and extensibility
This is very generic and I don’t have a list of requirements. However, it’s necessary for a platform to offer extensibility hooks to customise the feature set provided.
On the one hand, platforms like AWS Elastic Beanstalk provide very powerful hooks to override almost everything, and on the other hand, platforms like Google App Engine standard environments are very restricted and opinionated for anything you do.
Some things I want to able to customize that not all platforms support:
- Compute resources (CPU, RAM)
- Deployment strategy (in-place, green/blue, canary)
- Autoscaling strategy (request-based, utilisation-based)
- Filesystem and storage options (disks, nfs)
In a future ideal world, we shouldn’t need to specify CPU/RAM requirements either. Just run the application, and as requests come in it will get the resources it needs, and the platform will be able to absorb and distribute the load beautifully.
Good citizen
Another generic, and even more vague aspect I am looking for when evaluating a platform is if the platform is a good citizen within the ecosystem.
For example, if the platform comes with its own CDN, great. But can I proxy my deployed application with my own CDN if needed? Some Anycast platforms have issues in some setups.
Can I plug my own monitoring and observability product (e.g. Datadog) easily, or am I stuck with its own monitoring stack, if there is any at all.
Are there any hooks I can run generic commands/scripts for adhoc jobs I need during deployments, like provisioning external resources through Terraform? This would be a solved problem assuming that there is some kind of CICD workflow, but it’s something to watch for.
As I see it, the platform should provide good enough defaults to start with, whilst giving me hooks to customize my experience.
Developer experience (DX or DevX)
Developer experience is essentially how a platform feels like when using it, after considering every aforementioned dimension.
Is the platform intrusive to my application code? For example, do I need to change my business logic to be able to run on that platform? Examples here include App Engine, and most serverless function providers in some degree.
Can I accomplish my day-to-day tasks without wasting time reading badly written documentation, deciphering cryptic error messages, or fighting with broken CLIs and websites? Is it easy to troubleshoot and investigate issues with the infrastructure if and when they happen?
What are the abstractions of the platform? Do I need to configure every single piece of infrastructure similar to using AWS directly (e.g. VPC, subnets, autoscaling groups, scaling policies, IAM roles, IAM policies), or does it provide useful high-level abstractions with sane defaults. How much effort do I need to put to get my code deployed?
Do I really care that the platform is built on-top of Kubernetes (K8s)? No, I do not!
As a positive example, Fly.io with its built-in private networking which acts as advanced service discovery is really great.
Preview environments per pull-request, or easy to create environments per engineer, are crucial to have for faster feedback loop during development. This trend was commodized by the frontend platforms in the past few years, so now more platforms are supporting them.
This is just the tip of the iceberg of the things that make up a nice developer experience.
I have faith that the newer serverless products, alongside the managed AI platforms, will drive us towards a better future for traditional backend stacks too.
One of the most promising platforms I found was Modal, even though I usually dislike Infrastructure from Code tools. Modal combines amazing DX, great usage-based pricing, and they seemelessly disappear in your code. Unfortunately, they only support Python right now, but I am hoping they expand to more languages soon.
My complaint to AWS
Amazon and AWS have many issues at the company level, I can talk for months about them, but somehow AWS offers some of the most reliable and highly-available infrastructure in the industry.
If we focus on core products like EC2, S3, Lambda, DynamoDB, Route53, SQS, and a few others, you can pretty much build anything for insane scale. If only they fixed the developer experience of the platform.
They provide all the little pieces of the puzzle, without a preview of the final puzzle!
AWS Elastic Beanstalk was my favourite deployment platform a few years ago. Unfortunately, AWS abandoned it, and it shows. It was late to get Spot instances support, late to get Arm Graviton instances support, and there was hardly any major improvement of the product since its upgrade to the Amazon Linux 2 platform (back in 2020).
It combined everything, single instance, containers, managed autoscaled clusters, good default monitoring dashboard, simple CICD, and an amazingly extensible platform.
My guess is that the original internal team gradually moved on to other projects, or companies, and then the whole product entered maintenance mode. It’s not the first time this would have happened…
AWS wasted millions of dollars in numerous attempts to bring some of that Heroku experience in AWS, by building new services, instead of fixing, improving, and promoting Elastic Beanstalk. Services like AWS CodeStar (2017), AWS CodeCatalyst (2022), and even the promising AWS App Runner (2021), are all attempts to provide a better PaaS natively by AWS.
They are all going to fail. It’s obvious, to me at least, that most attempts after Beanstalk are mostly CV and promotion oriented projects. Who wants to get credit for improving an existing service, when they can advertise on LinkedIn that they launched a whole new service, and parade with announcement blog posts. Right? A new director can lead the launch of a new service, and grow a team from 3-4 people to 30 just within a year. That’s how directors get promotions. Been there, saw that, left after that!
Sometimes, starting with a clean sheet is the right choice, but in the case of Elastic Beanstalk, I believe that pushing it to the side until it rots, was the wrong decision.
Oh well, what do I know, I am neither Jeff Bezos, nor Andy Jassy 🤐
Conclusion
Okay, my ranting is almost over.
I probably looked into more than 50 products (see list of products/tools/platforms), open source self hosted platforms (e.g. Dokku, CapRover), platforms that deploy into my own AWS accounts (e.g. Qovery, Flightcontrol, WithCoherence, Stacktape), managed platforms (e.g. Fly.io, Render, Railway), and even the legendary Heroku.
All of them fail in some of the above core requirements. If it’s not pricing, it’s features, and if it’s not features, it’s developer experience.
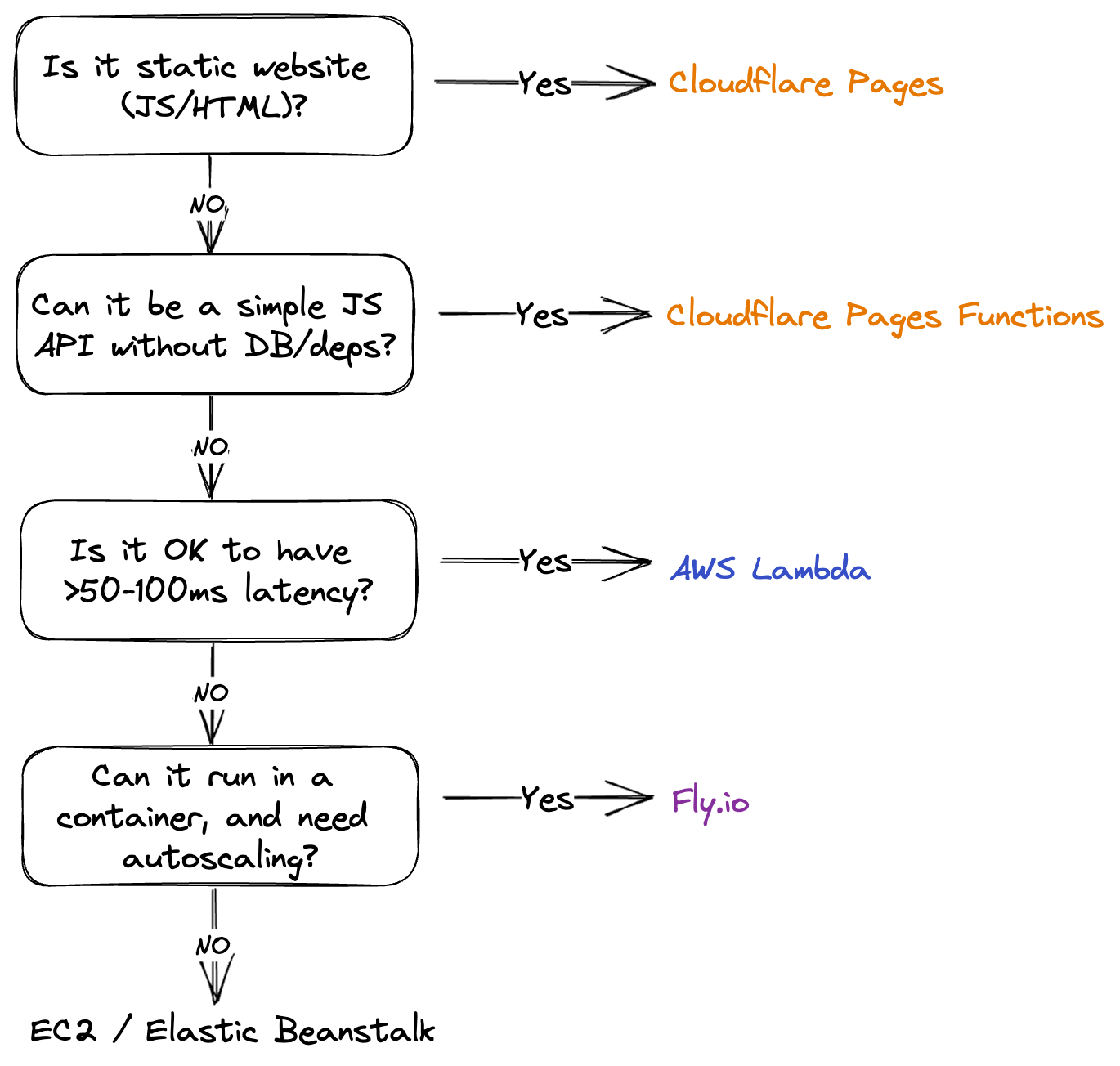
I currently settled on the following mix:
- Cloudflare Pages for websites.
- AWS Lambda for anything that can tolerate cold-starts and
>100mslatencies. - Fly.io for my autoscaled applications that work without in-place deployments.
- AWS Elastic Beanstalk or custom EC2 setup for my single-instance use-cases.
- AWS SAM and Terraform for Infrastructure as Code.
- Combination of AWS CodeBuild, Github Actions, and experimenting with Buildkite, for CICD.
A simple decision tree for the platform I use depending on my needs:
I basically have to setup the same things for every project I am working on, no matter how small or big. Infrastructure as Code templates, a CICD pipeline in a separate tool (when I need more than one stage) that needs access to the repo and my cloud account credentials, moving shared stuff into separate packages or copy-pasting them every time across repositories, etc.
Why not move all this boilerplate into a platform. Is it only my boilerplate?
The question remains
The Perfect PaaS: Does it exist? Can it be built? Or is it impossible?
The platform I envision. The platform I want.