The CI/CD Flywheel
Table of contents
- Introduction to the CI/CD flywheel
- The complete CI/CD flywheel
- Why do we need CI/CD
- Real world CI/CD
- Conclusion
In this article you will learn what CI/CD is, why you should use it, understand why it can be a competitive advantage for any team, and in follow-up articles I am going to describe how CI/CD is implemented in real-world teams I have been working with.
Introduction to the CI/CD flywheel
Let’s step through the full development and release lifecycle of releasing a traditional web application. We start by writing code, testing it, building it, shipping it to production, and making sure it works as we expect.
The full flow is what I call The CI/CD flywheel, and as we will see at the end, all the steps of the flywheel are what a CI/CD pipeline implements.
Product
It all starts by our customers, or potential customers, needing a feature.
This process involves discussing and coming up with a well-defined feature that we want to implement that will solve the customers’ issue.
Different teams follow very different methodologies for product decision making, so I am not going to get into that aspect here, but at the end of this step we end up with a bunch of engineering tasks that we want to implement.
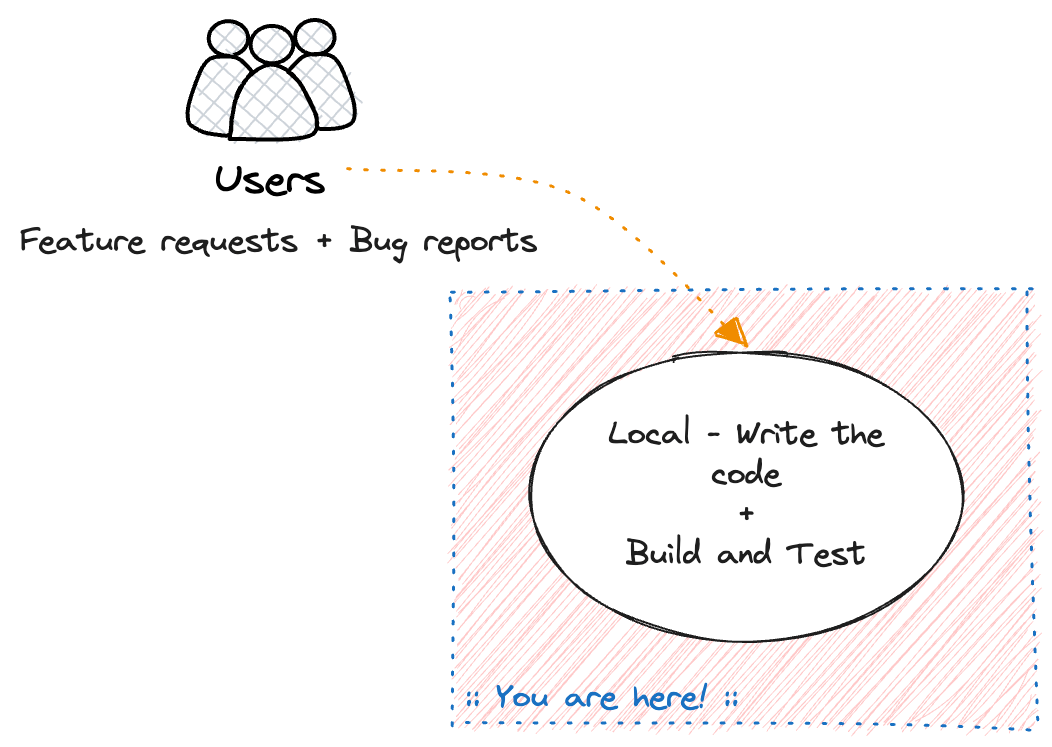
Local - Write the code
Once the feature requirements are defined, we write the code.
We do either locally on our laptop or PC, or in a remote development environment.
We use an IDE like Visual Studio Code, or a terminal based editor like vim.
At the end of the day we end up with some source code supposedly implementing the agreed-upon feature in our product.
Local - Build and Test
Once we have some code written, we want to test it to make sure it does what we expect.
Usually, we write some unit tests to test at the function or class level, maybe some integration tests to test a bunch of things together, and if we are feeling adventurous we add some end-to-end (E2E) tests. Most probably, if possible, you run the application locally for manual testing to make sure it does what you expect.
We repeat the process of writing and testing the code until the feature is ready.
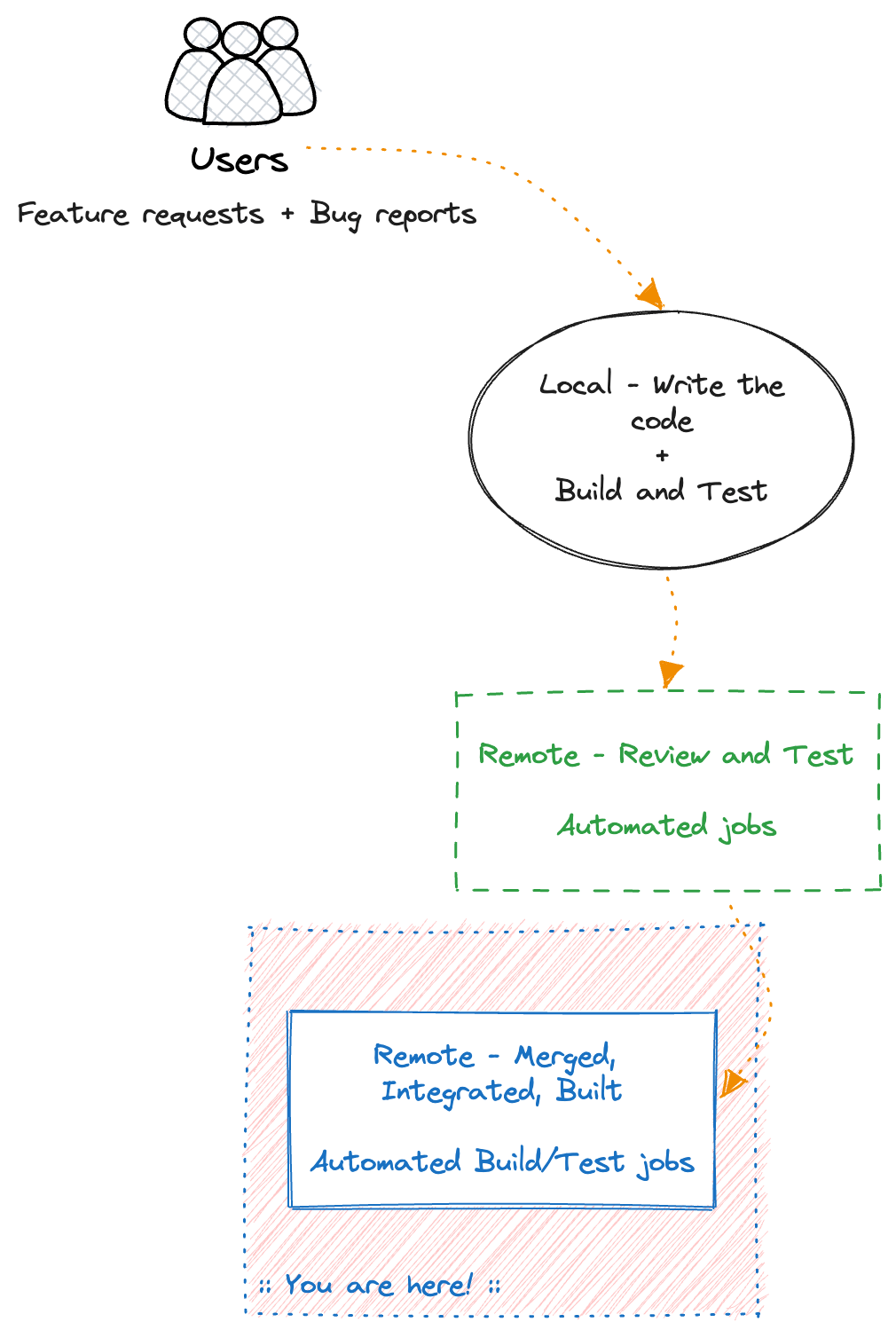
Remote - Review and Test
Once we are confident and satisfied with our code, we submit it for review by opening a Pull Request (PR).
Don’t worry, I know some of you just push directly without peer-reviews, but we are not all adrenaline-junkies…
Most (good) code review systems (e.g. Github) allow you to run several jobs on each Pull-Request (PR) to build and test the changes. In these jobs we run any kind of tests we have, and even do more elaborate tests that take more time to complete, and therefore we don’t want to be running locally every time we change something in our code that would hinder our productivity.
Ideally, these jobs run in isolated environments that do not interfere with any production system, and can provide reproducibility in every run.
In some other code reviews systems, we are not able to do much other than building the code, and running the basic tests (unit, integration), so we just do that. Either way, we want to take advantage of this functionality to do testing of our code changes before merging them to the main branches used by everyone else in the team/company.

Remote - Merged, Integrated, Built
After the code review is done, we merge our changes into the main branch(es) we use for production releases.
Once again, we want to run tests to make sure the code is correct and properly “integrated”. Keep in mind that at this point potentially several other engineers have also merged their changes into the same branch.
The term “integrated” here means that we bring changes from multiple engineers and integrate them all together into one source, that needs to be built, tested, and then released as one. Even if there are no code-related conflicts, there could be logic/business oriented conflicts and issues because of this merging.
At this step, we run extra analysis jobs like static code analysis, or security vulnerability checks, or end-to-end tests that could take several minutes or hours to complete, and more advanced tests.
This is often the last step we will run most of our suite of automated tests without direct customer or manual interaction.
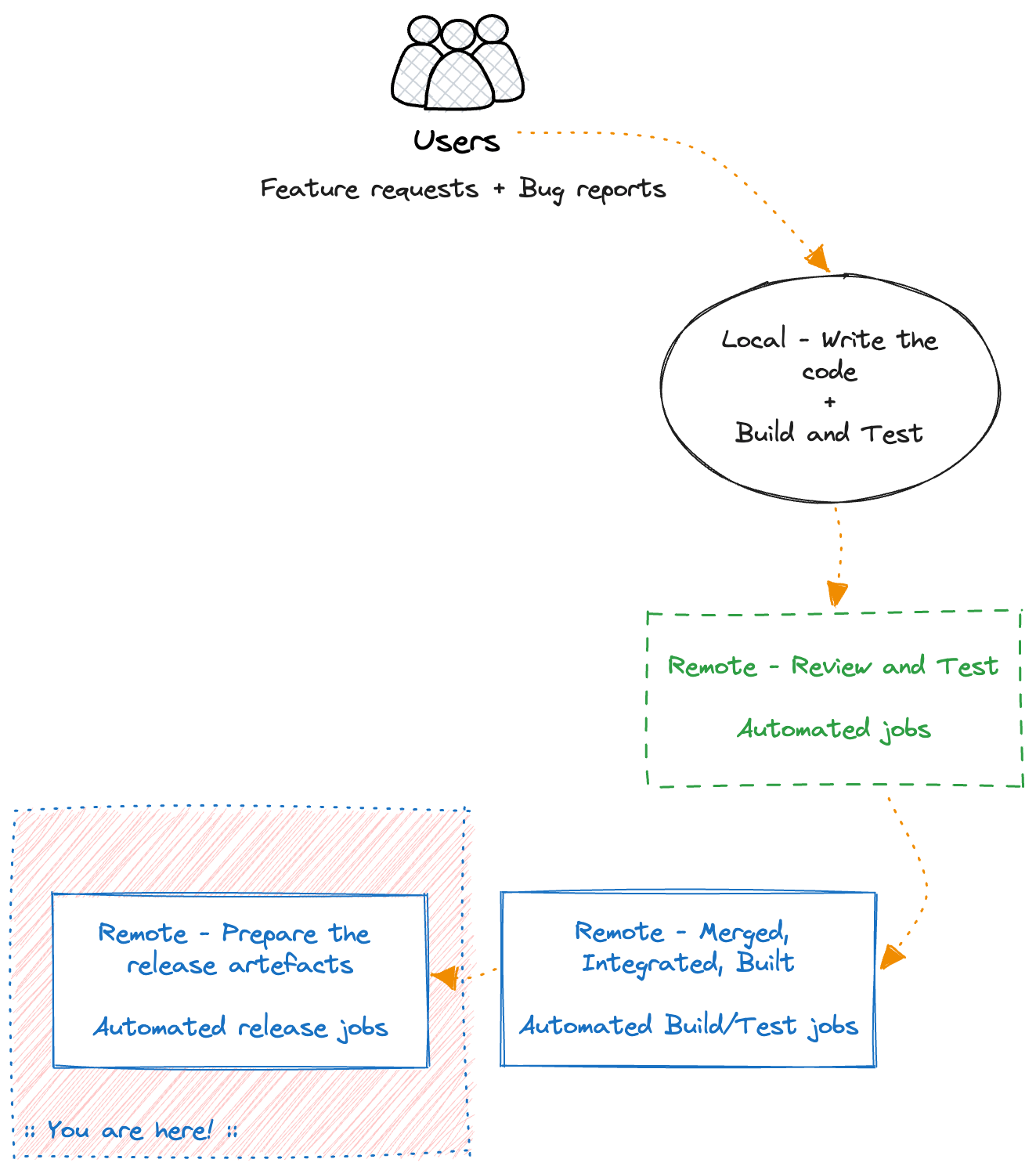
Remote - Prepare the release artefacts
Once everything passes, we need to build the release artefacts that will get deployed into our actual running systems.
Depending on the application this could be platform-specific artefacts (e.g. .apk) that we will upload to the mobile app stores (Apple Store, Google Play Store).
It could be Docker containers that we publish to one of the container registries (e.g. Dockerhub, AWS ECR), or the binaries for our CLIs, or the static files for our website, or any other artefact that our build process generates.
Regardless of the type of our product, this is the step where we generate the artefacts to be delivered to the production systems.
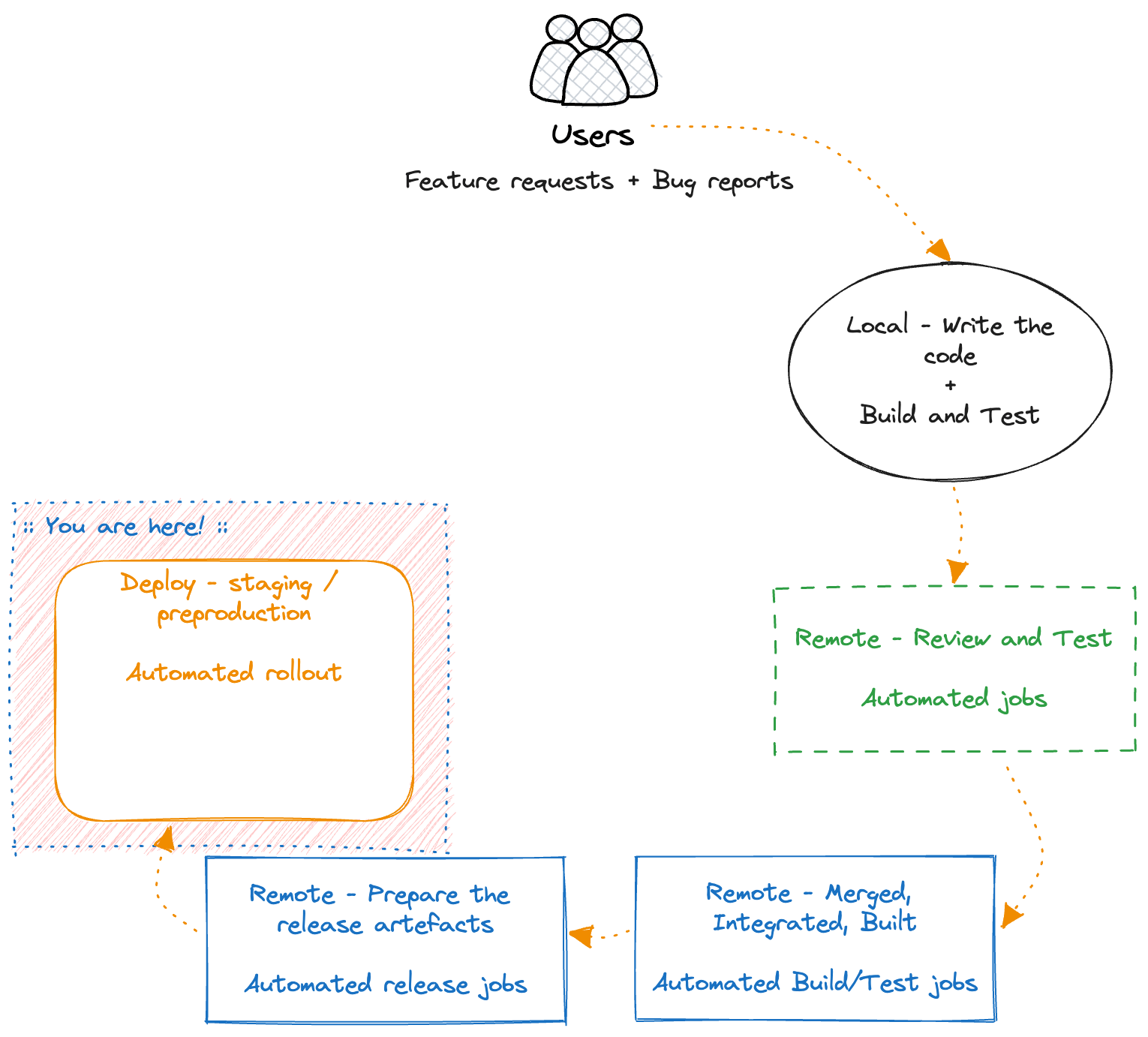
Deploy - staging / preproduction
We wrote our code, we built it, we tested it, and we generated the release artefacts. It’s time now to deploy it.
At this step we take the release artefacts from the previous step and ship them to wherever our product is released.
If it’s the app stores, we will follow their corresponding process. If it’s a website or a backend server we will deploy the artefacts to the servers. If it’s a firmware update we will deploy it to some device lab with actual devices and automatically install it on them.
Finally, there are some rare cases where the deployment will happen in a manual way, by an actual person, to a medium that we cannot reach with automation and requires physical presence.
A key aspect for this step is that we should do the deployment on an environment that is not the one used by our customers, or at least not all of them at once by using private beta programs with few testers only (e.g. in the case of a mobile app). This is what we call staging or pre-production environment(s).
This is not always possible, and some teams prefer to just ship to production (if you are one of those - at least use feature flags!). Personally, I always prefer having at least one staging environment.
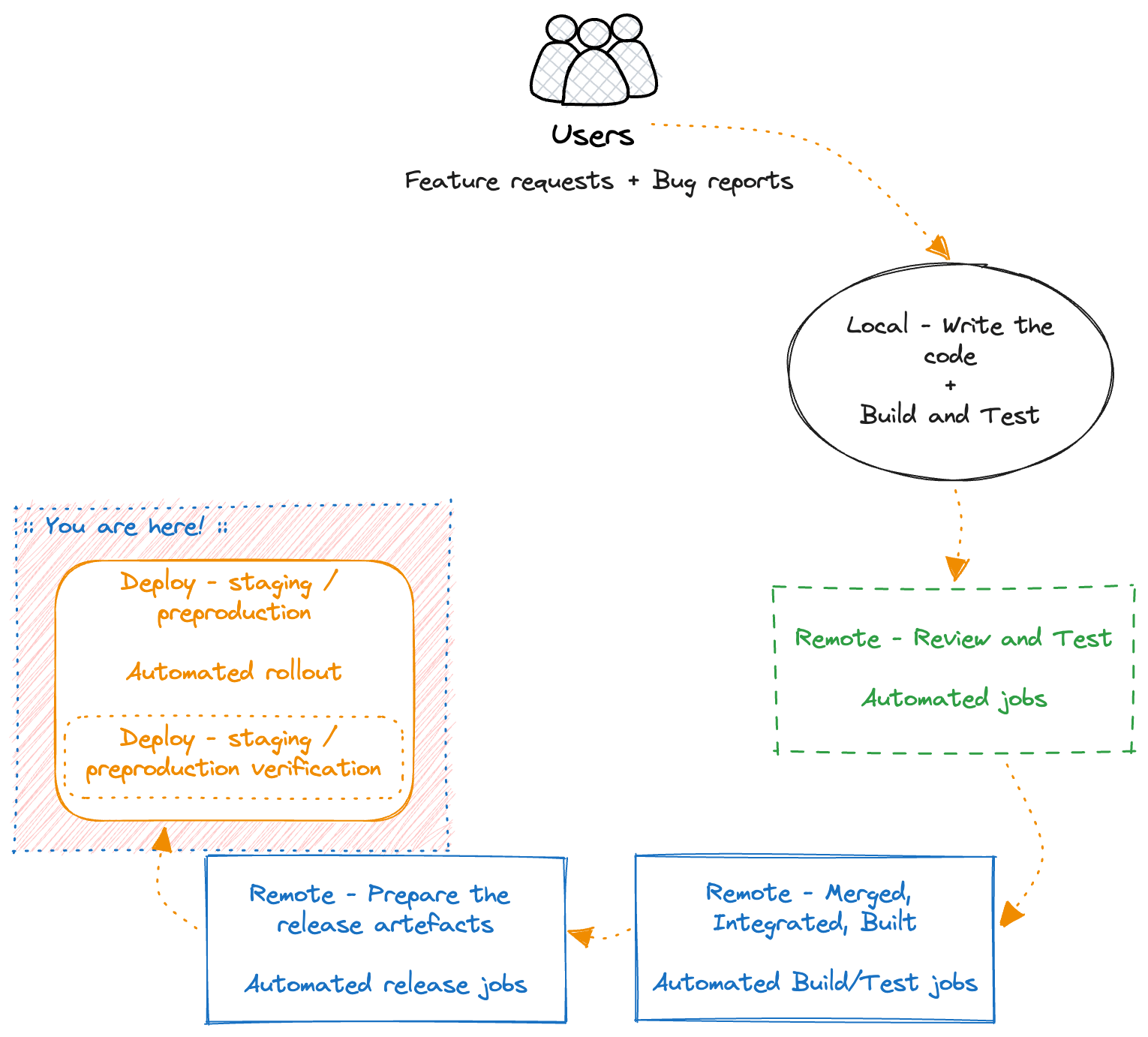
Deploy - staging / preproduction verification
We deployed our changes to our staging/preproduction environment, and it’s time to verify that no alerts or alarms are going off, and that all the features we implemented work as expected, old and new.
This verification could be done in various ways, automated, manual, in a few seconds, or across several hours. It all depends on the actual product.
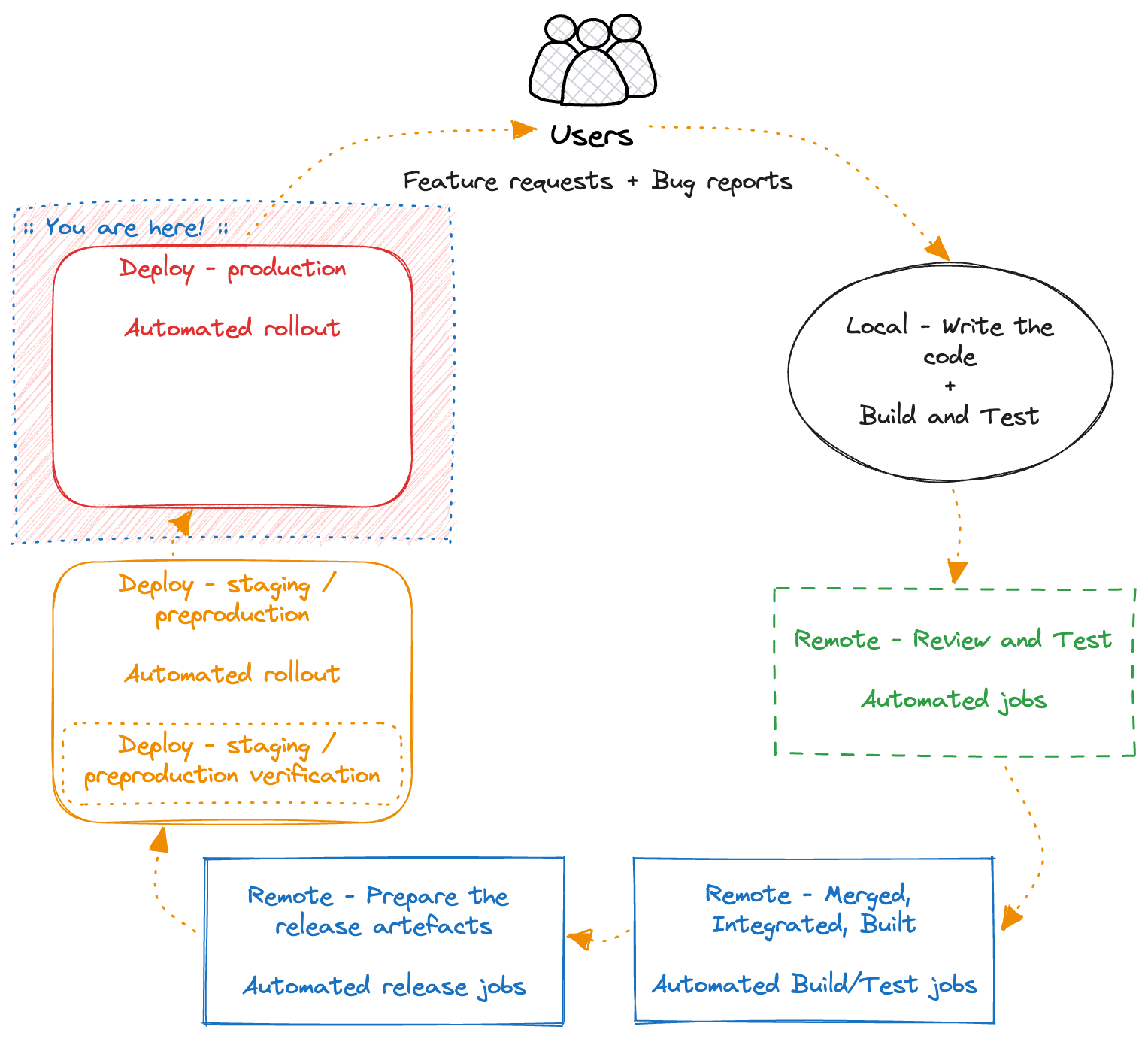
Deploy - production
Finally, we deploy our artefacts to the production systems used by our actual customers.
This process should be similar to deploying to our staging environment(s), albeit in a different scale and ideally in a gradual way across all of your infrastructure.
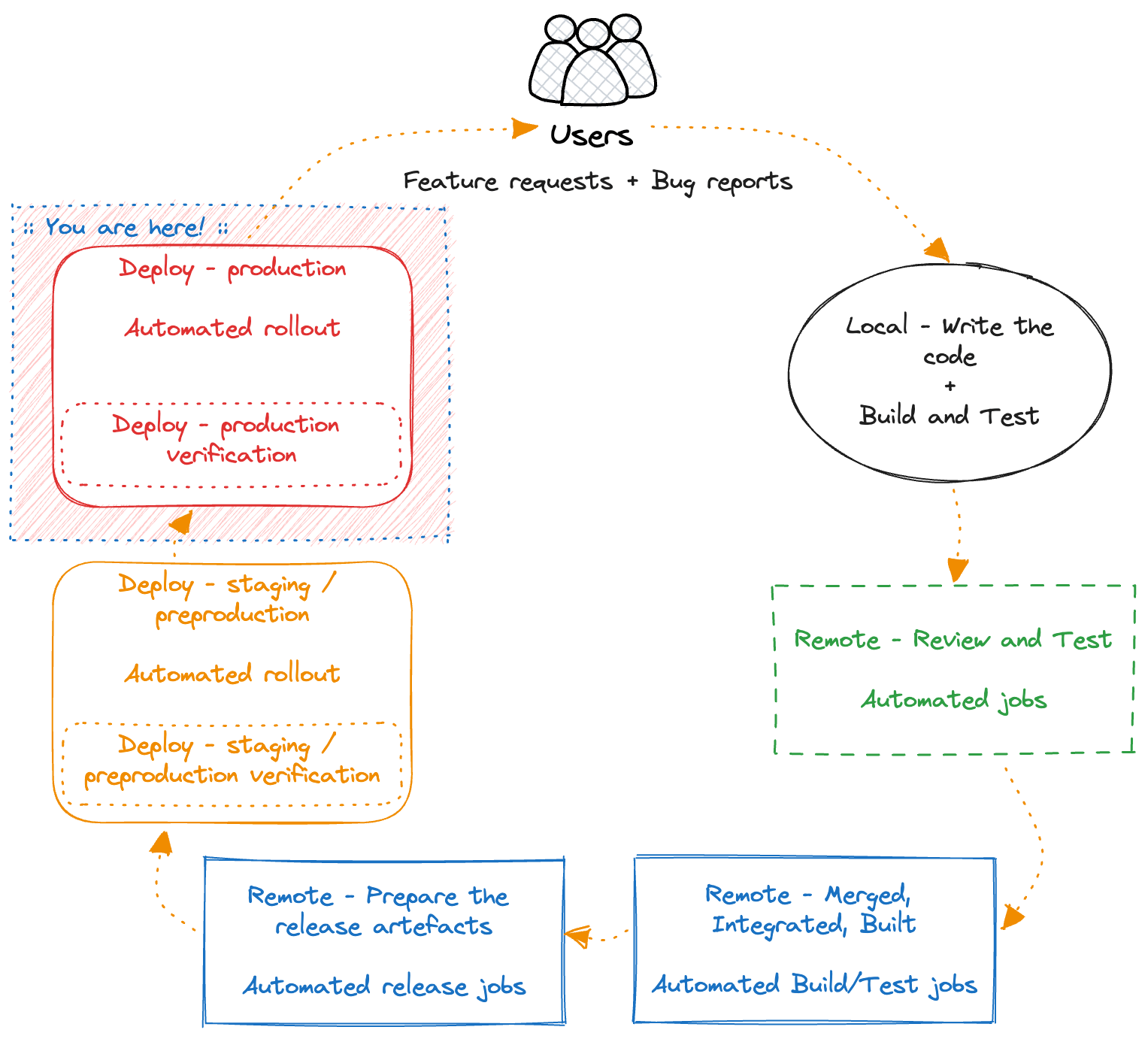
Deploy - production verification
For one last time, we need to verify that everything works fine, no customer is negatively impacted by the newly shipped changes, and that we didn’t break anything that was previously working.
To succeed in this step we need to have proper monitoring and observability of our applications. There is a whole bunch of things around observability but at the end of the day, you should have alerts that will notify you when something is negatively impacting your users.
Customer feedback / New feature requests
Our changes are in production, used and loved by our customers, so now we repeat the whole process again. Customers are asking for more features, or they complain about something and we need to fix.
We go back to our editor, write some more code, and go through the whole cycle again.
The complete CI/CD flywheel
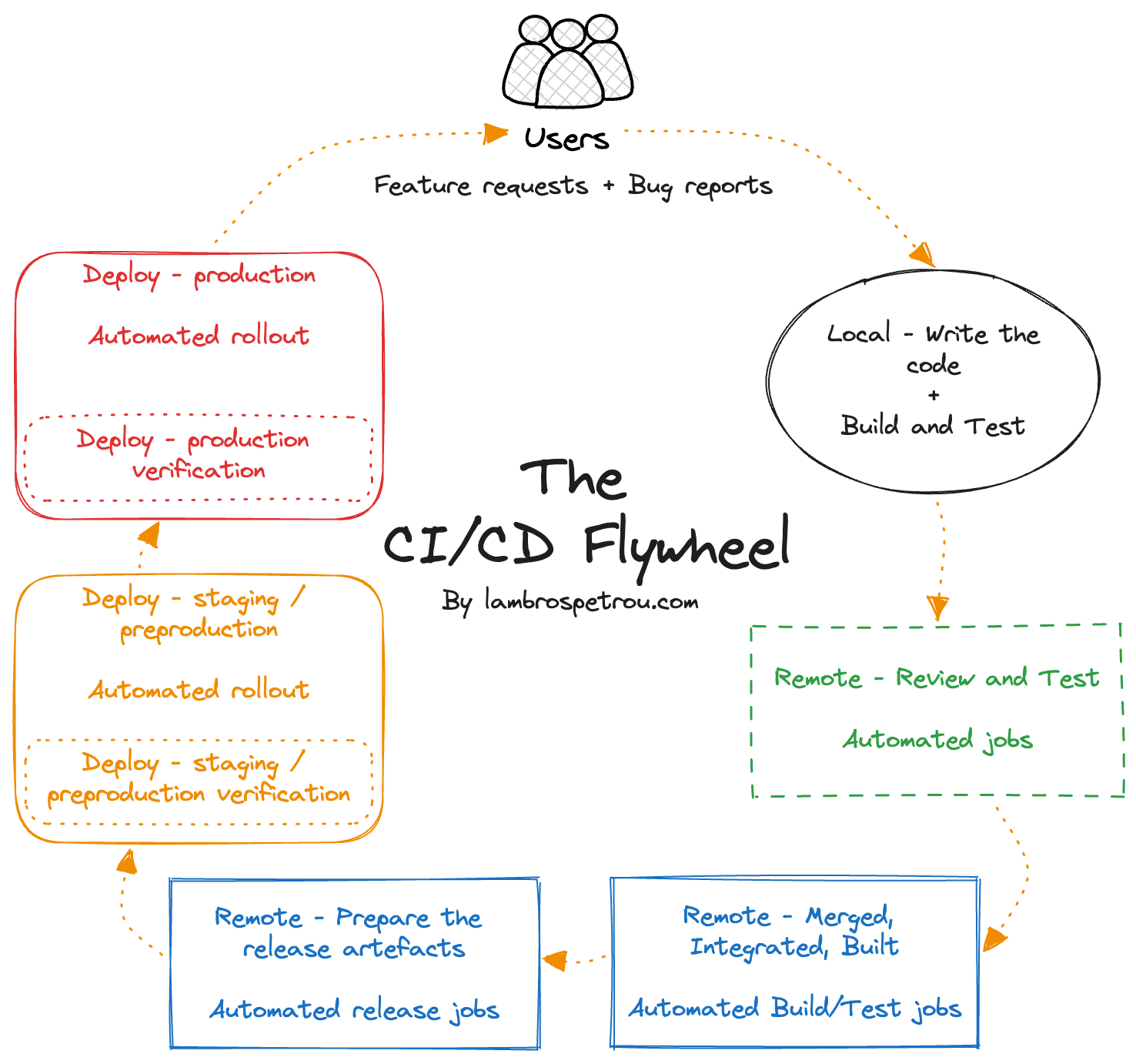
The whole process we went through is what I call The CI/CD flywheel.
In traditional publications, it is also called Software Development Life Cycle (SDLC), but I like flywheel better because it emphasizes the looping aspect.
We can see that the whole development cycle, the idea/customer request, writing code, delivering an artefact to customers, getting feedback, and going back to ideas, is a simple loop. The faster you transition from one step to the next, the faster you deliver value to customers.
One way to cycle through the flywheel faster, is to remove certain steps, for example the verification steps, or even the whole preproduction environment. Indeed, this will shorten the circle. However, there is a hidden trap in this thinking.
Removing validation steps will cause you to actually go through extra iterations. Inevitably, broken things will be shipped to customers, and we will need to repeat the process more times just to fix bugs that could be prevented in the first place.
Catching issues later in the process is much more expensive than catching them in an earlier step. The latter steps in the flywheel (deploying, verifying and getting user feedback) are often more time-consuming than executing the earlier steps (writing and testing code), therefore doing the early steps more times is more beneficial than doing the latter steps more times.
In the diagram below we can see how the steps of the flywheel map to the CI/CD phases: Continuous Integration (CI), Continuous Delivery (CD), and Continuous Deployment (CD).
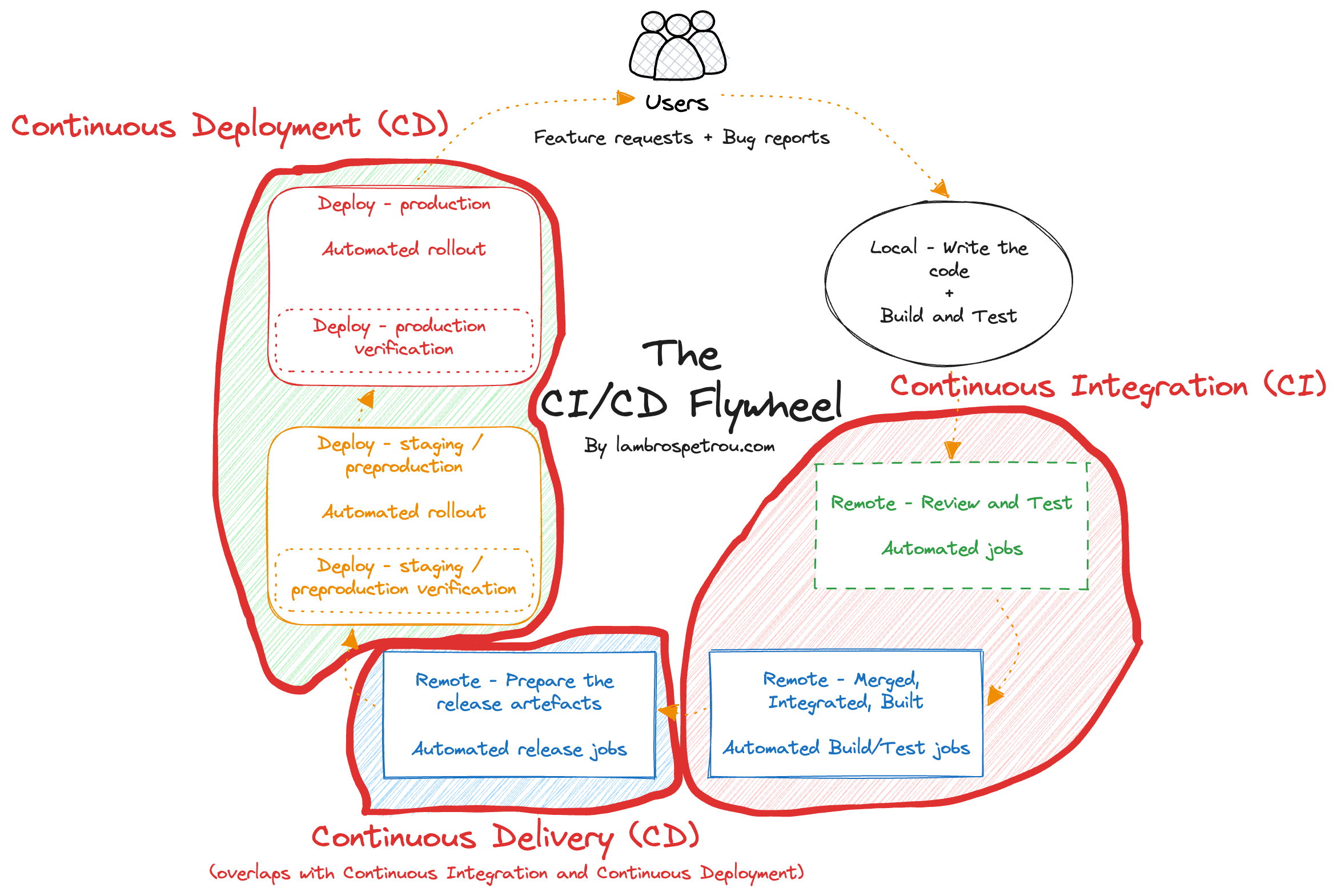
Most of the flywheel belongs into at least one phase of a CI/CD pipeline.
Therefore, having great CI/CD systems is crucial in order to allow us to move faster, and delivering value to our customers safely, reliably, and continuously.
Why do we need CI/CD
We have explored the CI/CD Flywheel that gives an overview of the CI/CD process. Let’s explore some of the concrete benefits we can get from implementing CI/CD in practice.
Business benefits
Ship value to customers more often
Implementing new features, fixing bugs and issues detected in early stages of the CI/CD flywheel, and automated delivery of the release artefacts to the different environments, all ultimately contribute to shipping business value to customers faster and more often.
Earn and retain customer trust
With a variety of automated tests, early detection and fixing of broken features, gradual rollout of new features, and finally, automatic detection of faulty releases, we significantly reduce the risk of breaking features that customers depend on. Or, when we break features, we can quickly release their fixes.
In this way, we earn the trust from customers, and retain it forever reducing unsatisfied customer churn.
Fast experimentation feedback loop
Practicing CI/CD efficiently means that we can experiment and test new innovative features faster and more often.
Engineers are not being slowed down in cumbersome manual release procedures, and most importantly they are not risking in breaking real customers with unpolished or unfinished features unexpectedly.
CI/CD enables the development of features that would otherwise take a lot of back-and-forth in discussions among the different stakeholders until its decided that it’s worth doing.
Within a few days or even hours, a feature can be tested in a subset of users, or even in a staging environment without impacting customers, and take a more informative decision based on real data.
Attract the right talent
Anyone in a creative role, including software engineers, designers, product owners, and others, likes to see their ideas and creation used by customers as soon as possible.
The rapid development feedback loop that CI/CD provides is a great selling point to attract people into working for a company.
Who wouldn’t want to work on a team that allows them to work and ship new ideas every day, straight to customers, in minutes or hours, instead of months!
Cost reduction
The earlier an issue is detected, and fixed, the less costly it is to the business. Let’s examine some scenarios.
Scenario A - reckless
- We implement a new feature, and ship it directly to production so customers start using it.
- Customers start complaining in social media, and file support tickets, because something broke.
- The support team and on-call engineers are scrambling to see what’s broken, implement a fix, and then ship it straight to production again.
Scenario B - half-assed
- We implement a new feature, and ship it to an environment where a team of Quality Acceptance engineers (QAs) will need to do manual testing.
- After a few hours, or days, the QA team managed to test our changes but detected something is broken.
- They send it back to the engineering team, they implement a fix, and they send it back to QA again.
- After a few hours, or days, the QAs approve, and we now ship the change to production.
Scenario C - better
- We implement a new feature, and merge it in the main codebase.
- The change goes into the CI/CD pipeline where the first step is to run some automated tests.
- One of the automated tests fails and stops the pipeline.
- We see that the automated test suite failed, check which test failed, implement a fix, and merge again.
- The tests pass, and the change is delivered to our staging environments for further validation and then goes to production.
There are thousands of other scenarios that could happen in practice, but I chose these because they showcase well the difference in mentality, and more importantly the cost of fixing an issue.
In scenario A, the issue went straight into production, and customers noticed immediately.
This not only hurts the business reputation, but it also costs a lot more in person-hours.
We will spend a lot of time debugging the customer complaints until we figure out the root cause, then implementing the fix, and shipping to production. If we are lucky, the change we did for the fix won’t break something else…
In scenario B, we are not as reckless as in scenario A, and we have a team of dedicated QAs that will do manual validation of changes.
This sounds very inefficient (and it is), but it is actually used by thousands of companies, even today. The QAs will often catch issues before reaching production.
However, the issue is the overhead of communication between the engineers and the QAs, in some cases with multiple back-and-forth iterations. In addition, a code change just sits in a queue of changes that the QAs gradually go through and verify, which also introduces extra delays.
Finally, imagine all this happening twice. This is a lot of man-hours just spent on verifying that a change works as expected.
In scenario C, we spent a few minutes and automated (most of) the tests that the QA team would do manually in scenario B, and added them in the automated test suite that runs in our CI/CD pipeline.
The tests ran and failed just a few minutes after merging our change, and within a few minutes we implement a fix and merge again.
So, let’s recap what each scenario cost the business:
- Scenario A: X hours of debugging and going through customer complaints & business reputation risk.
- Scenario B: Y hours/days of developers and QA communication, but less risk of the issue reaching customers.
- Scenario C: Z minutes of automated run on a remote machine, and less risk of the issue reaching customers.
In majority of cases, it holds that X ~= Y >> Z, which means that even though initially it seems that having a full CI/CD pipeline is more work and more steps, in practice it will save us a lot of time.
I hope it’s clear how big of a cost reduction it is to detect issues early on and to automate their verification.
Fun fact 👉🏻 CI/CD is similar to Anton Cord, introduced by Toyota. The farthest the issue was detected in the pipeline the costlier it was to fix and it would cause more defects. The same approach was adopted by tech companies like Amazon and Netflix, and then more.
Technical benefits
Code quality
Due to integrating changes to the main source code repository multiple times per day, we guarantee that the changes always build, and pass the relevant tests.
Gone are the days that engineers spent weeks implementing features in isolation, and then spending days trying to merge their changes together, solving major conflicts, or even rewriting big chunks of code to make it work.
Comprehensive tests
Because our CI/CD pipeline will run automated tests for each code change in remote environments, we are encouraged to add more tests that will cover more scenarios we want to check.
We can have tests that need elaborate setups, and that would be very time consuming to setup manually, like privacy and security checks, or performance regression detection, or testing our change on multiple versions of a browser, or multiple devices, etc.
Overall, due to having automated test suites running on isolated environments we can do things we cannot afford to manually do locally on every code change.
Automate repetitive tasks for reproducibility
Doing manual steps over and over again inevitably leads to mistakes.
QA testing sessions usually include manual actions. Publishing release artefacts by manually running commands locally on your laptop is problematic.
I faced such issues early on in my career. For the release of our mobile app we were using our own laptops to build the corresponding artefacts for each app store (iOS, Android, Amazon Fire). Due to differences in our workspaces, once or twice, we shipped faulty releases. However, when a different engineer was trying to reproduce the issue on their laptop, it wasn’t failing, due to local workspace differences.
This was a nightmare to debug.
A good CI/CD process will always guarantee that everything runs from a clean state, so that every time you execute the same steps, you get the same result.
Automating as much as possible is a gift that will never stop giving! 🎉
Build once, use everywhere
When using CI/CD to build and deploy our software, we get the nice benefit that the same artefacts we build in the first steps of the pipeline are the ones being propagated to all the environments thereafter.
This means that we can attribute anything that happens in the pipeline, like test failures, or deployment issues, or even issues caught in production, to a single artefact, which ultimately will lead us to the offending code changes easier and faster.
Another benefit from releasing the same artefact everywhere, is that we can reason more easily about what’s running in each environment/stage without worrying about inconsistencies among the environments.
Controlled rollouts and faster Mean Time To Resolution (MTTR)
Automatic deployments across environments enables the use of controlled, gradual, rollouts.
We could be doing gradual rollouts on a small percentage of customers each time, or even rolling out changes continuously but hiding the feature behind feature flags and only enabling it for certain customers.
This allows monitoring to detect failures impacting customers, and rolling back the newly released changes automatically. This is easy and efficient to do in a CI/CD managed environment since each change that gets released is usually small and its rollback won’t cause havoc to customers.
Doing this manually, even if doable in some cases, would be very error-prone with elaborate manual steps.
Real world CI/CD
In follow-up articles I will provide a bird’s eye view of some real-world CI/CD systems and procedures that I personally experienced throughout my career.
I want to showcase some examples of how companies use CI/CD in different ways, and at the same time how they follow the same principles that make up the CI/CD flywheel!
In all these real-world system the fundamentals are the same. The goals are the same. The benefits are similar. The implementation is different.
CI/CD systems we will explore:
- Amazon Retail / LOVEFiLM
- Gitflow development (2 branches), 2-3 stages (beta, gamma, prod) and 2 regions
- Amazon Profiler
- Trunk based development, 2 stages (beta, prod) and 1 region
- AWS/Amazon CodeGuru Profiler
- Trunk based development, multi stage (beta, gamma, prod), multi region
- Meta WWW
- Trunk based development, tiered production deployment (C1, C2, C3, … C9)
- Others…
If you want to see something specific please reach out @lambrospetrou 😅
Conclusion
This article introduces the CI/CD flywheel, and maps its steps to a CI/CD pipeline for building, testing, deploying, and verifying our software products.
I truly believe that embracing and implementing fast automated CI/CD pipelines is truly a competitive advantage for any team, and any company, of any size! 💪🏼 🚀